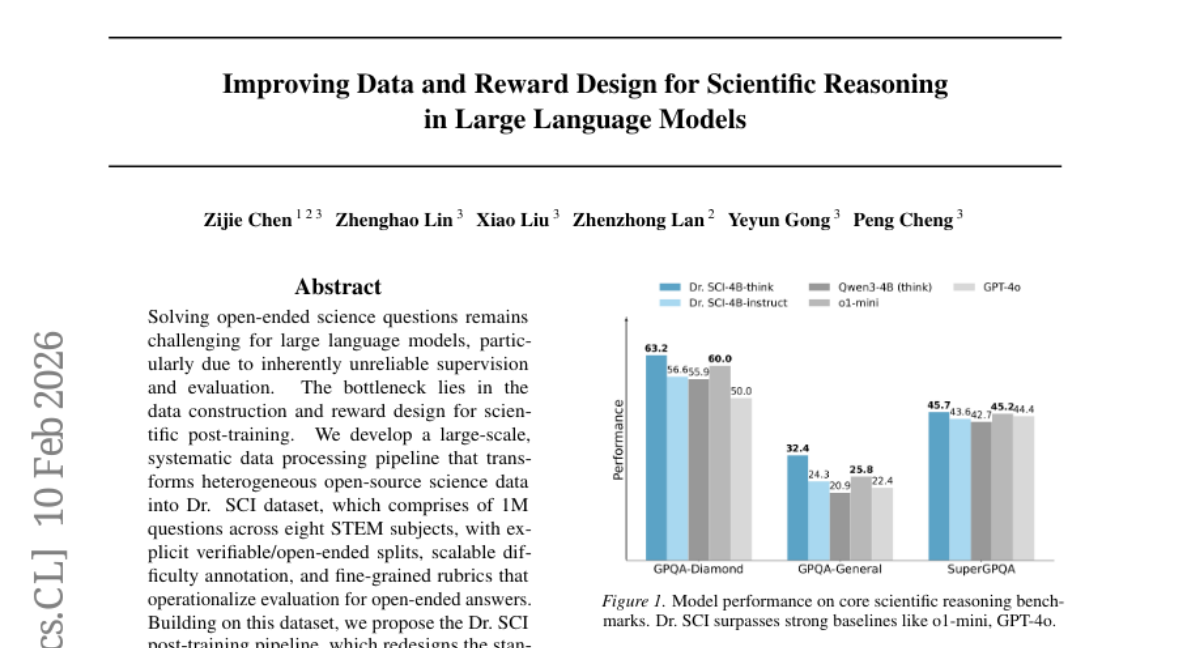
None defined yet.
Improving Data and Reward Design for Scientific Reasoning in Large Language Models
SEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks